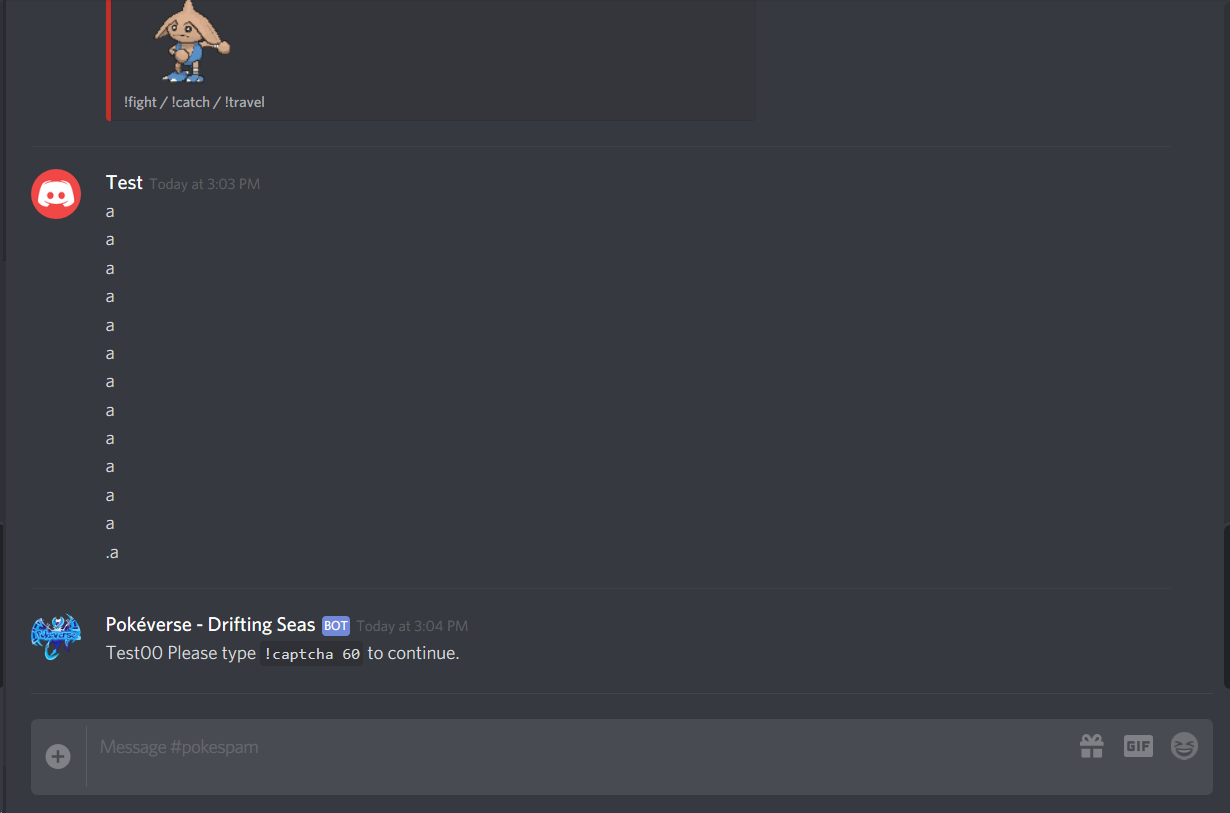
The XType command doesn’t properly type the text (it types nothing at all actually). I’m using OCRExtract because the variable doesn’t change much (0.7 is the scanner % and works fine). Here’s the photo:
The first step is to check if OCRExtract works ok.
What is the value of ${text}?
If OCRExtract fails, then the next tests are:
If you test OCRExtract command with the FIND button, does it work then?
If this also fails, then please provide the OCRExtract input image that you are using, plus a screenshot of the website where the “value to be extracted” is.
So, I tried using echo… and apparently it doesn’t save properly onto the variable is what I’m seeing from OCRExtract, although when I click find on OCRExtract… it works fine and can locate it. I’m using Firefox if that helps.
Side note - How does OCRExtract work if there are multiple instances of the image to be OCR’d in the same image?
I tried using it before - It had the same problem, the OCRExtractRelative wouldn’t pick up anything - even though when I click Find, it works.
I added echo (This is ${text}) and nothing appears:
[status]
Playing macro 0 test
[info]
Executing: | XClick | 500, 700 | |
[info]
Executing: | OCRExtract | CaptchaR_dpi_120.png | text |
I’ve used it before - still, the problem persists. Is there something wrong inherently within my code? I can switch back, but that doesn’t solve my issue of it not working here. What seems to be the problem with my code? I don’t think it’s an issue of image finding or text extracting because they seem to work fine when I use find, as well as the log says it can accurately find it; the problem is, nothing appears when I use echo, meaning that it’s not extracting anything.
Sure, it doesn’t really matter, I just need to know how it works, if there’s a simple of example of it extracting a text, it could even be on this forum page! That would really help,
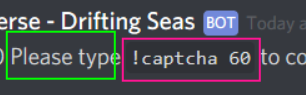
Do you happen to have discord (it’s a messaging platform, that I would like to extract something from, and that’s where the website is - you need an account though)? I have looked at it and I’ve tried to copy it, I just dont really see where I went wrong with my code to be honest If you could get it - add Test00#0619, otherwise from what you can see, I can switch the code to use relative with green and pink boxes, I just don’t understand what I did wrong basically, or why it isn’t copying