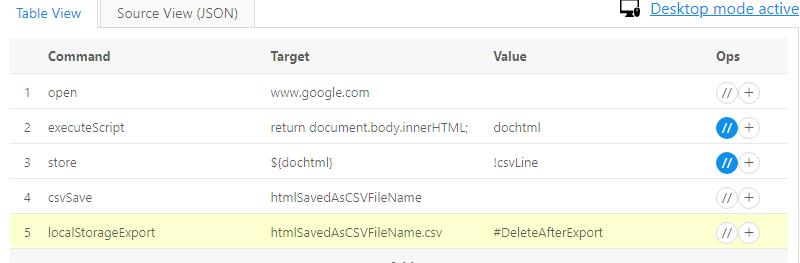
I want to capture the whole html code of a page and put it in a csv file. I didn’t find a command like CaptureEntireHTMLpage
It sounds simple, just use SourceExtract with a regex like .* but it doesnt work on special caracters and linefeeds.
I managed a this regex : [<>=-_.:;"’/û,€éèêçàïëü&|()%!+*’\’?$\w\s]*
but it doesn’t work for all web pages
So is it possible to have a regex which select all kind of characters or to have all the html code extracted and saved in a csv file or directly on the hard drive like the LocalStorageExport command?
Thanks for the good problem description. As you said, doing this reliable for all kind of websites via sourceExtract can be tricky. => It sounds like what you need is a function “Save Page As” (HTML only), like Chrome and Firefox offer it.
This is not yet available, but is on our todo list for the July upgrade. And once we have it, LocalStorageExport will allow you to export it to a local file.
If you want, you can stay informed about a9t9 software updates with
our free a9t9 newsletter.
The feature “sourceExtract for the complete HTML page” has not been added yet.
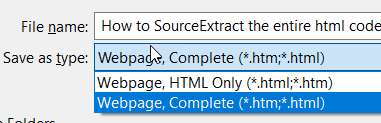
But if your main goal is to save the website HTML, you can do this meanwhile by simulating “Ctrl+S, Enter” with XType. The “DemoXType” macro that ships with Kantu shows this feature. With a few more keystrokes you can also select the “Webpage, Complete” option. Then you save all images, too.
Thanks, I made that work, though it was difficult to determine where the file would get saved, so I had to go hunting for it, and when I found it, it wasn’t really in a place where I would expect it. If there are any hints about how to determine/control where it goes, others may appreciate it. Thanks.