I’ve been using the OCR Space API through ShareX for several months and rarely encountered issues. But today, it keeps returning all Japanese text in the wrong order. Characters can appear in the wrong line, or even in the wrong order in the same line. I tried several different kinds of text and even typed some myself, and the result always seems to be the same. However, when I typed it horizontally, the OCR worked properly (but Japanese text is normally vertical so that isn’t particularly useful).
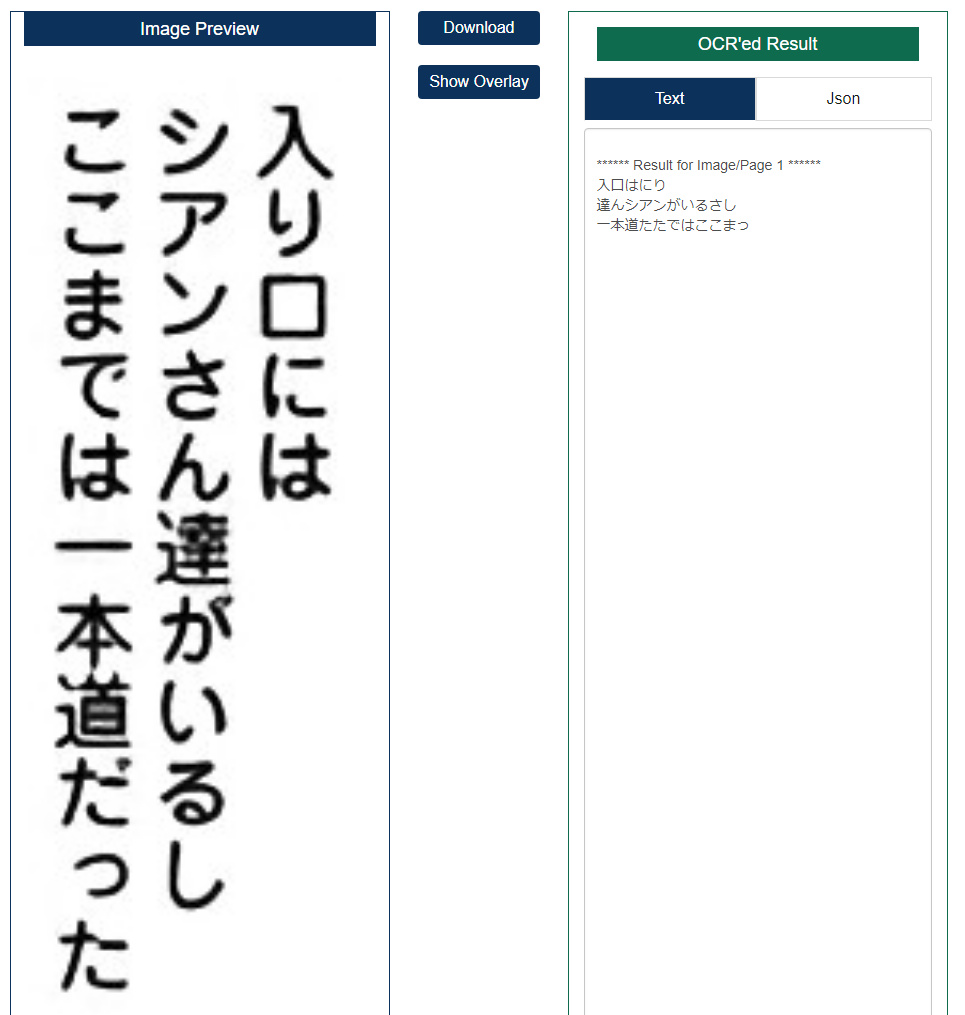
This is an example of some pretty clear text. As you can see, the characters are all in the wrong order. For the first line, for example, it has “入口はにり” when the correct order is “入り口には” (Japanese is read left to right, top to bottom, in case you’re not familiar with the language).
I tried using a different PC and even had friends who live in different countries try and got the same result. What seems to be the issue here?
